Few-Shot In-Context Imitation Learning
via Implicit Graph Alignment
Abstract
Video
Consider the following problem: given a few demonstrations of a task across a few different objects, how can a robot learn to perform that same task on new, previously unseen objects? This is challenging because the large variety of objects within a class makes it difficult to infer the task-relevant relationship between the new objects and the objects in the demonstrations. We address this by formulating imitation learning as a conditional alignment problem between graph representations of objects. Consequently, we show that this conditioning allows for in-context learning, where a robot can perform a task on a set of new objects immediately after the demonstrations, without any prior knowledge about the object class or any further training. In our experiments, we explore and validate our design choices, and we show that our method is highly effective for few-shot learning of several real-world, everyday tasks, whilst outperforming baselines.
Key Idea 1) Learn a general model that can align two novel objects in a way that is consistent with a few examples. 2) Use it to find a trajectory of alignments needed to complete arbitrary tasks from a few demonstrations, without any prior knowledge about the object classes or any further training.
Imitation through Object Alignment
We address few-shot imitation learning as a problem of finding a trajectory of task-relevant alignments between two objects. Inferring such a trajectory of alignments from just a few demonstrations, without any prior knowledge about the object class or any further training, allows us to complete everyday robotic tasks immediately after the demonstrations by moving one object relative to the other, recreating the inferred alignments, as can be seen in the video on the right. We achieve this by learning a task-agnostic conditional distribution of alignments using a graph representation of objects and an energy-based model, which jointly infers task-relevant parts of the objects and how to align them in a consistent way with the provided demonstrations.
Generalisation Through Object Deformations
To learn the previously discussed general conditional distribution of alignments we need a large and diverse dataset of consistent alignments between different instances of objects from the same category. We achieve this by utilising a correspondence-preserving shape augmentation method, which allows us to create an arbitrary number of objects which are aligned in a consistent (but task-agnostic) way. For example, we can create many different aeroplanes and motorcycles, while ensuring that their specific parts (highlighted as green and blue spheres in the visualisation) maintain the same relevant alignment in all of them.

Object Alignment Representation Using Heterogeneous Graphs
To effectively learn the proposed distribution of alignments and enable generalisation to novel objects, we first create a general representation of alignments between two objects using a heterogeneous graph. We do so by first clustering point cloud observations of the objects, locally encoding their geometries, and connecting created nodes with bidirectional edges (yellow and green). It allows the model to focus on specific parts of the objects and varying alignments between them. To propagate information from the demonstration and test alignments we connect them with the directional edges (grey) achieving a graph representation that is suitable for making predictions about whether the test alignment is consistent with the demonstrated ones. Below you can see the visualisation of the procedure used to create such a graph representation.
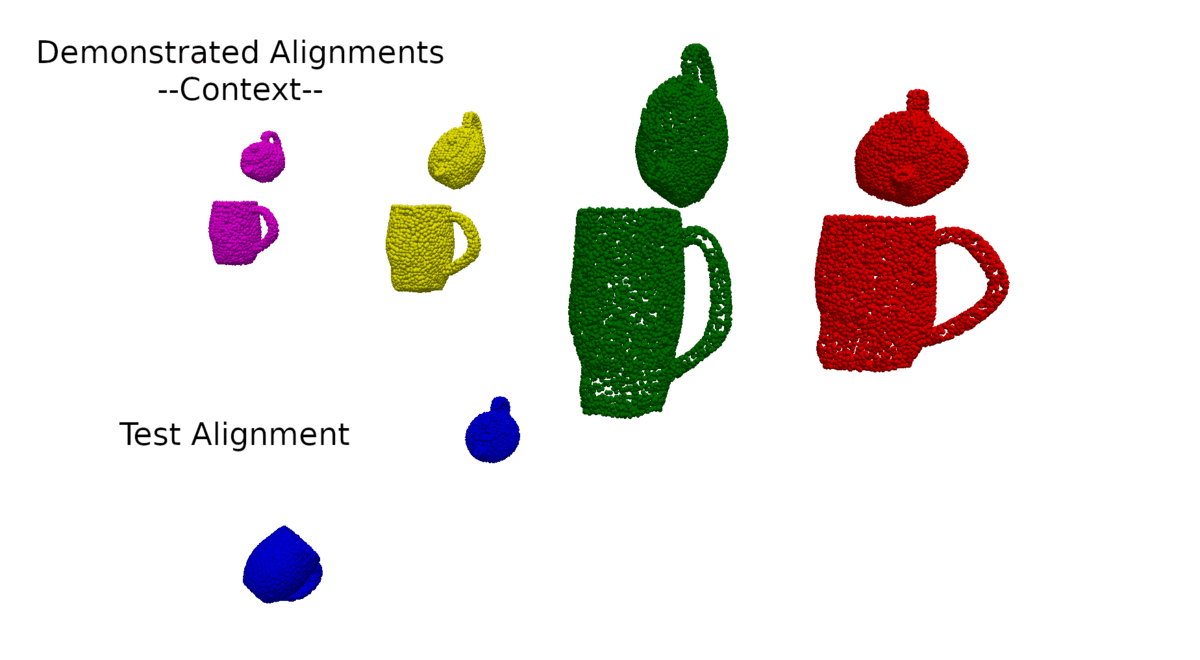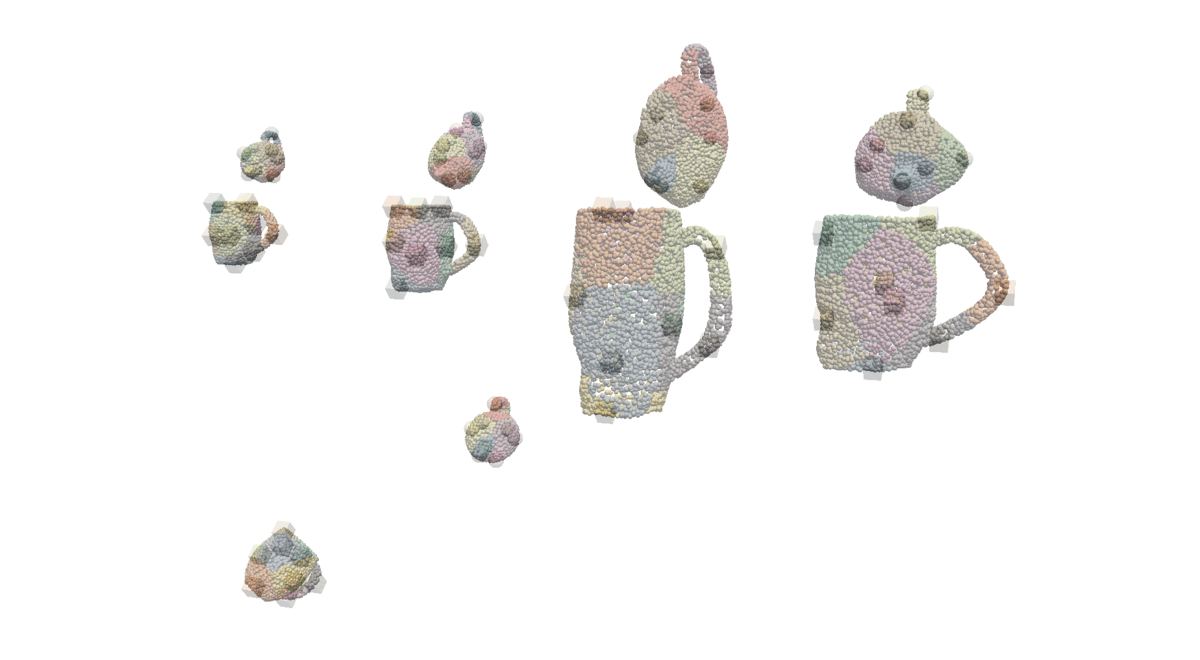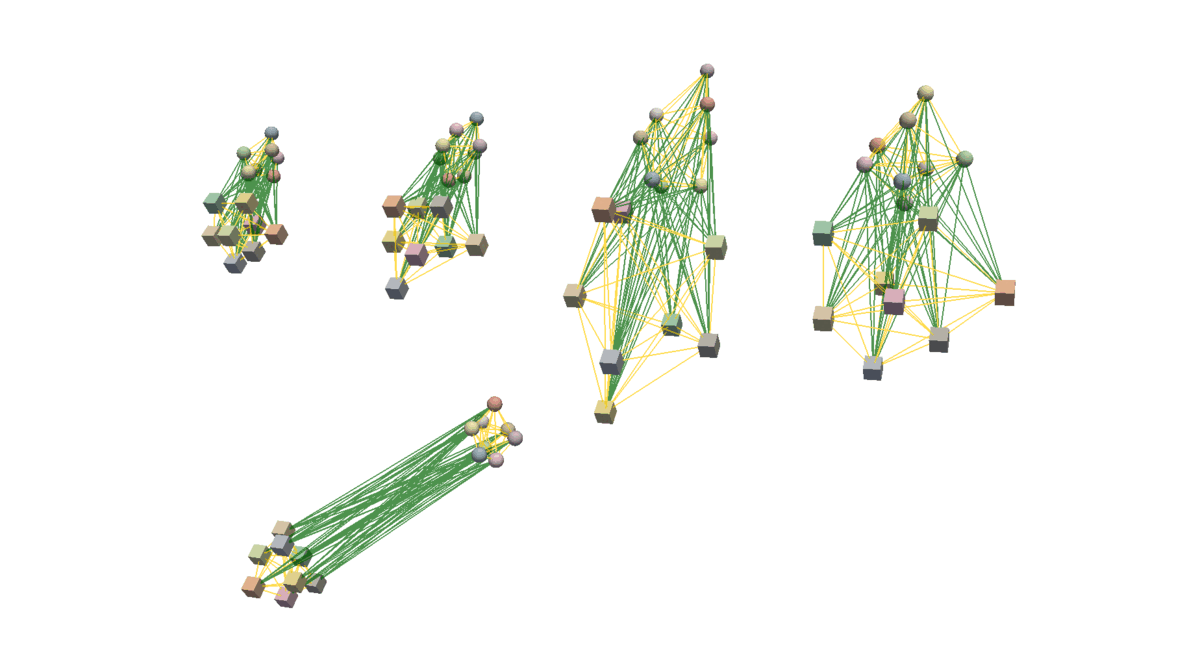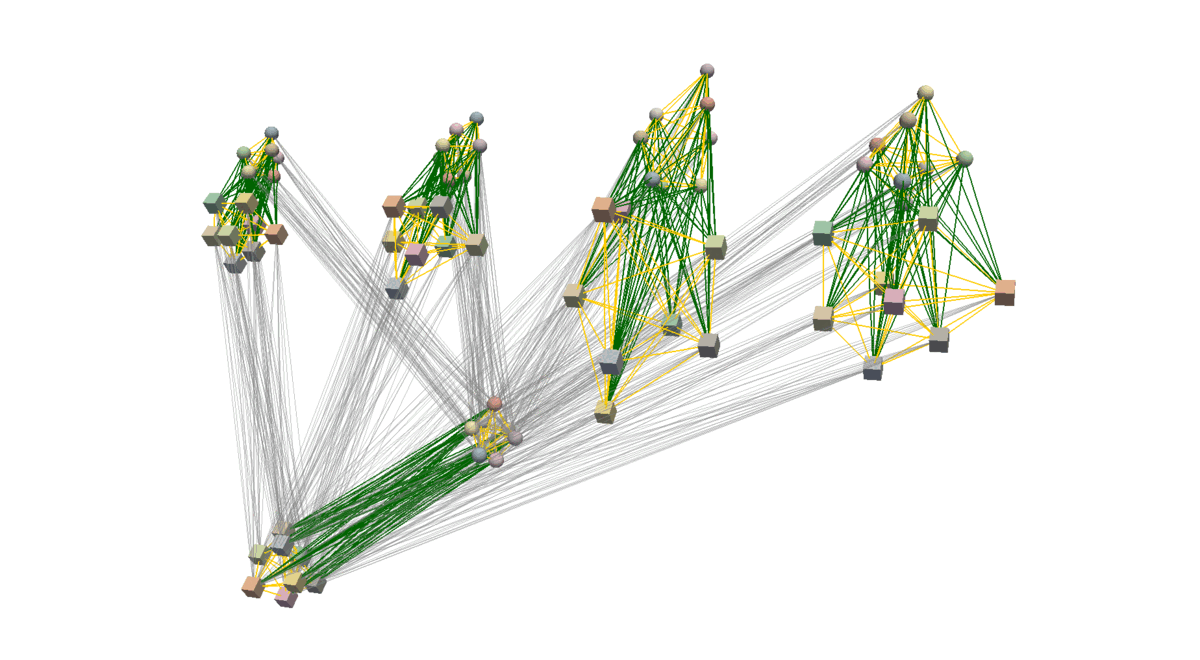
Learning Implicit Distribution of Alignments

Having a structured graph representation and a diverse dataset of alignments to learn from, we then employ an energy-based model to implicitly learn the previously described distribution of alignments. Intuitively, our energy-based model compares the test alignment with the demonstrated ones and determines whether it is consistent (low energy) or not (high energy). By moving one object relative to another (for example in a 2D plane), we can visualise the energy landscape the model learns for a specific sample. On the right, you can see the evolution of the learnt energy landscape during training. Here, the red ball represents the ground truth (where the minimum of the function should be).
Optimisation at Inference
Using the learnt conditional distribution of alignments as an energy model, we can find an alignment of novel instances of objects that is consistent with the demonstrations at inference by performing a gradient-descent optimisation. Below you can see an example of such an optimisation procedure when visualised using our devised graph representation. Intuitively, we are moving part of the graph in the direction that minimises the predicted energy.
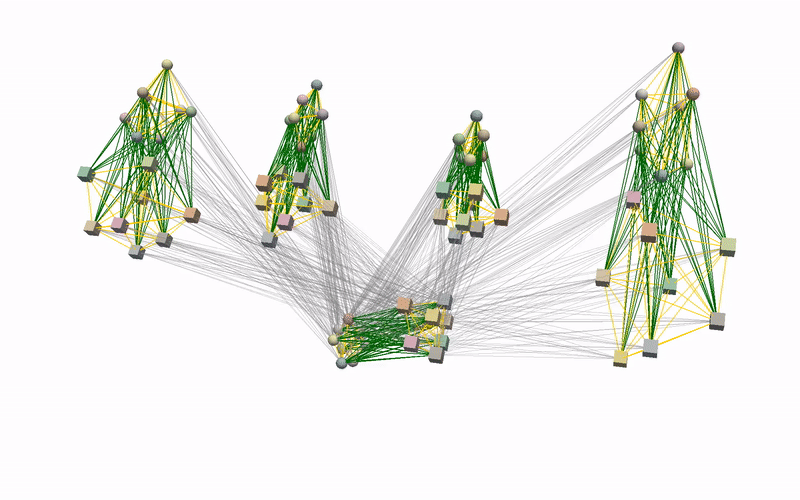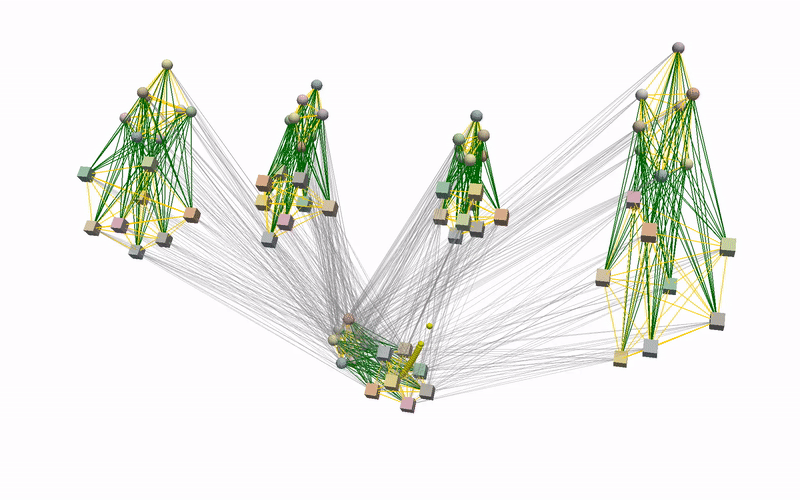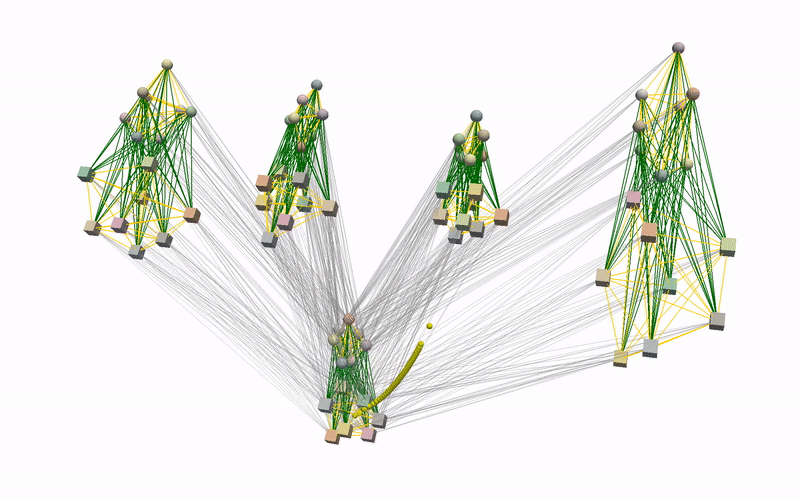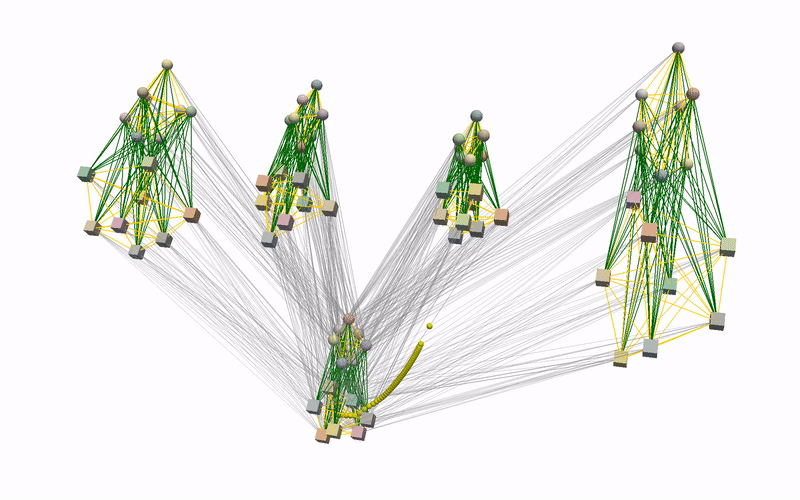
To better understand what is happening, we also provide visualisations of the optimisation procedure in the input space of the learnt model, i.e. segmented point clouds. Magenta, yellow, green, and red point clouds represent the demonstrated alignments between objects, while the blue point clouds represent the test alignment that is being optimised.

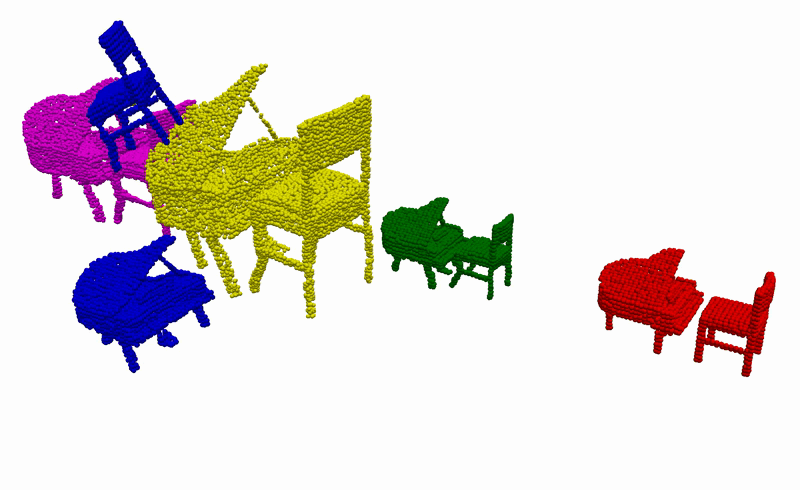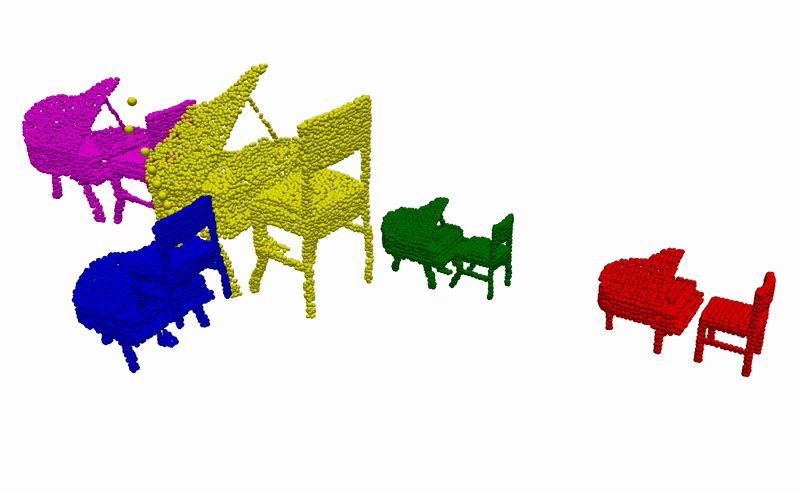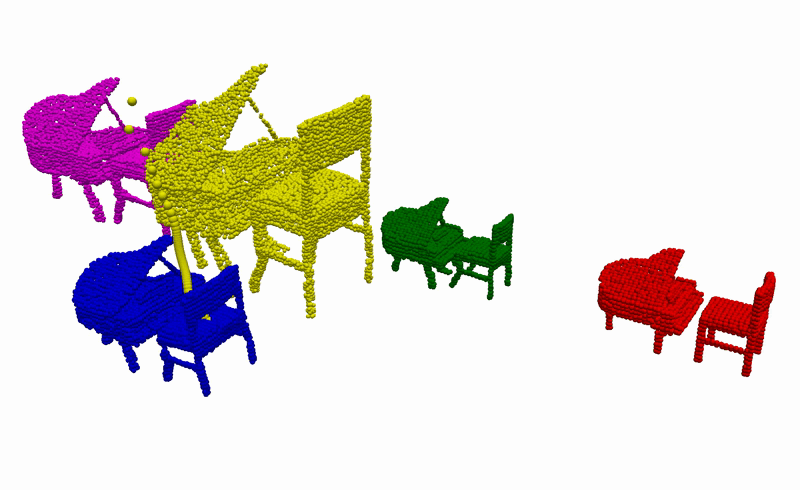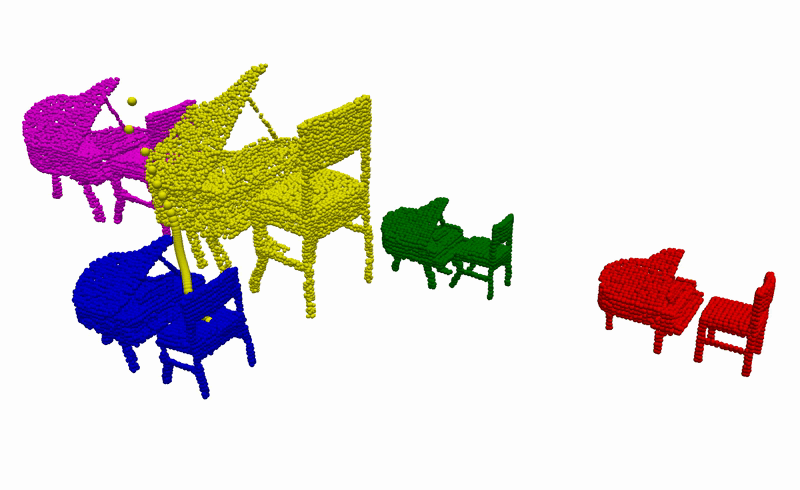



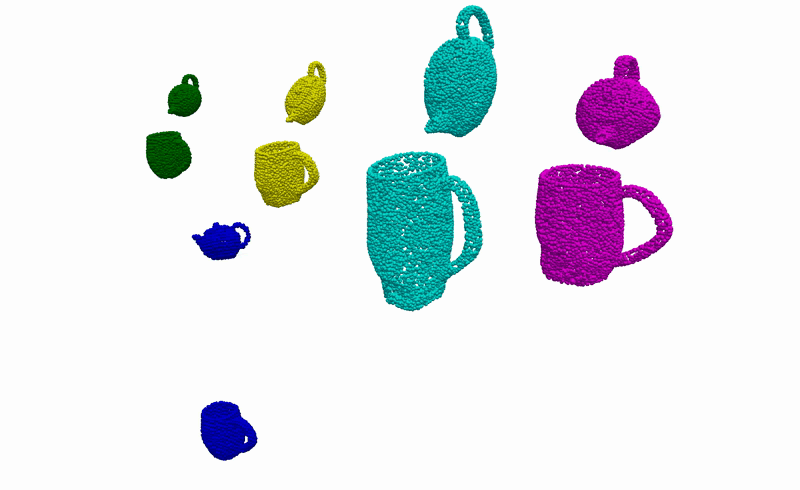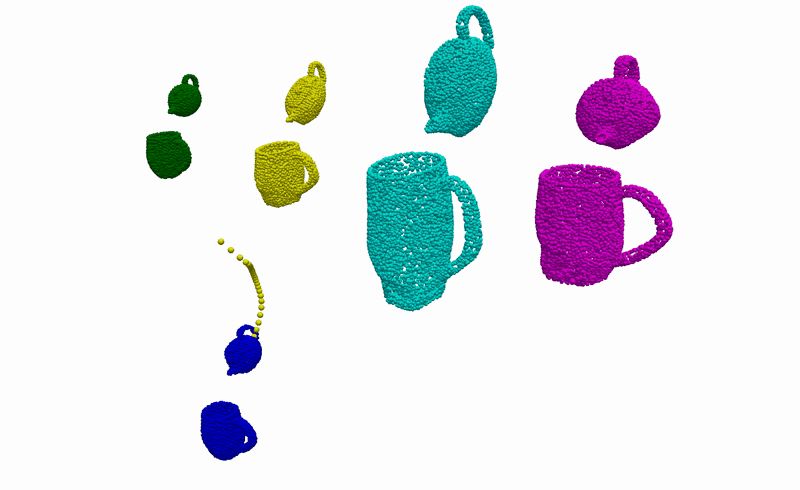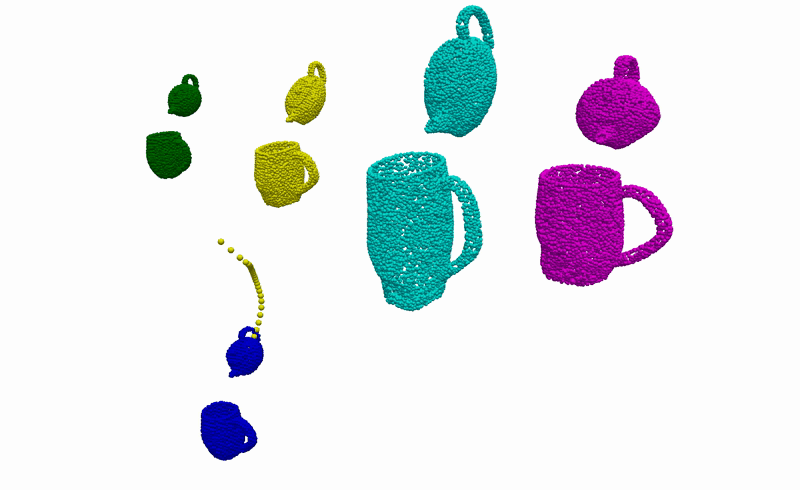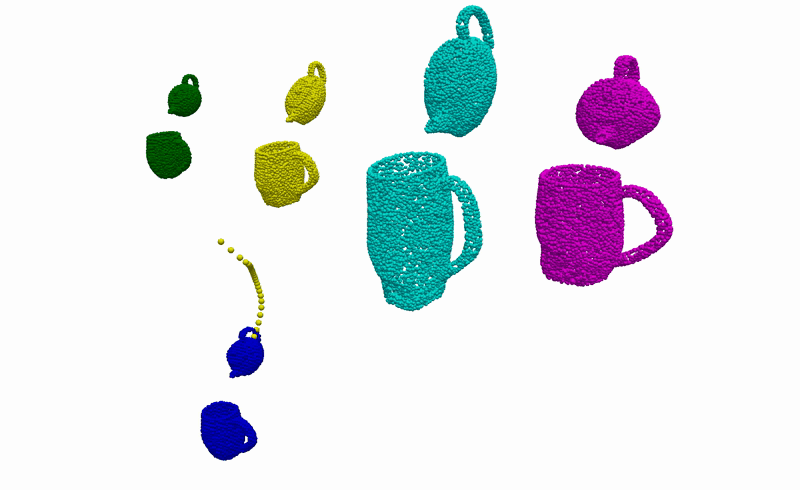

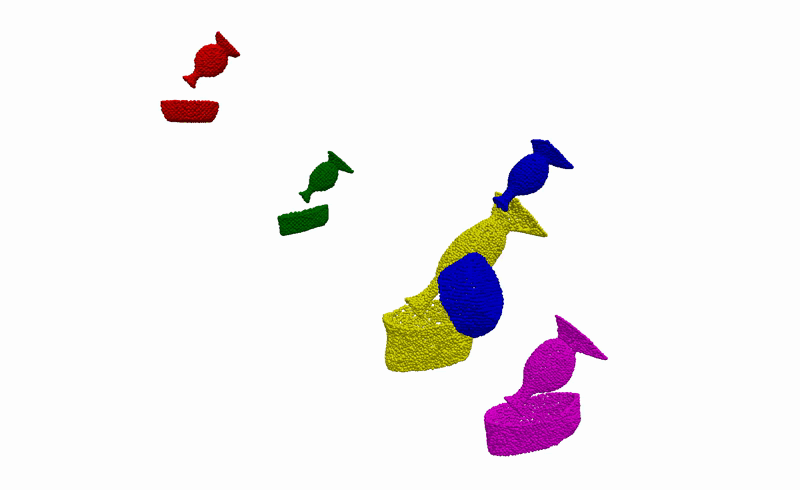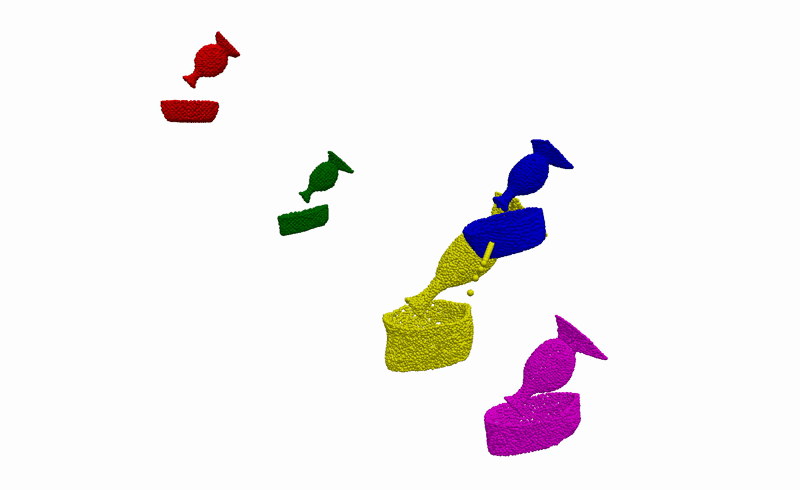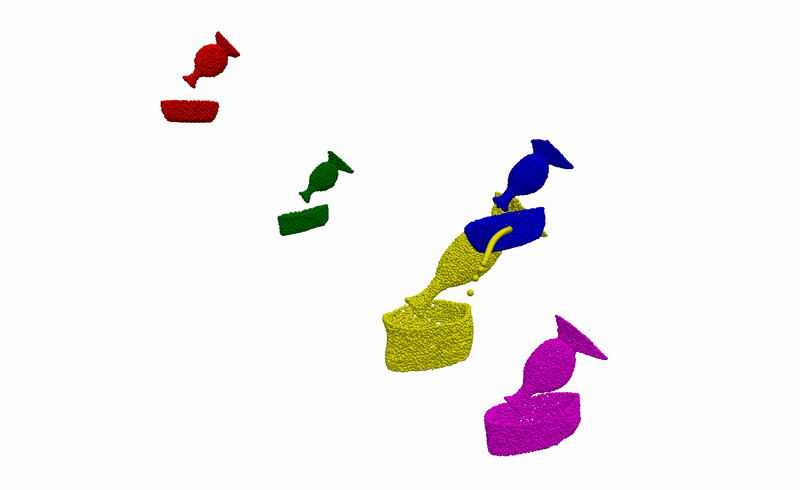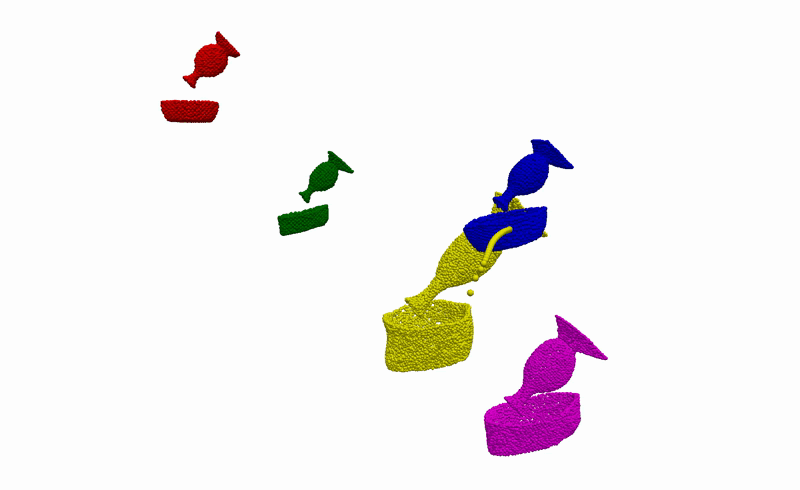
Real-World Deployment
Having the ability to infer the alignments between objects that are consistent with the demonstrations, we can then use it to complete everyday robotic tasks in a few-shot manner without the need for any further training or prior knowledge about the objects. Below you can see the real-world deployment of our method on 6 everyday robotic tasks. Note that, for all of our experiments, we use a single model trained on the diverse synthetically generated dataset described previously.