Our Research
For Edward Johns' Google Scholar profile, click here.
For the lab's YouTube channel, click here.
For a video summary of the lab's recent work, click here.
Below are the key peer-reviewed publications from the lab.
Click on each paper title for further information.
Learning a Thousand Tasks in a Day
Kamil Dreczkowski, Pietro Vitiello, Vitalis Vosylius, and Edward Johns
Published in Science Robotics, 2025
Mini abstract. We develop new highly efficient imitation learning paradigm, which enables teaching a robot 1000 distinct tasks in just 17 hours. This efficiency comes from decomposing trajectories into "alignment" followed by "interaction" phases.
Neural Stochastic Flows: Solver-Free Modelling and Inference for SDE Solutions
Naoki Kiyohara, Edward Johns, and Yingzhen Li
Published in NeurIPS 2025
Mini abstract. Stochastic differential equations model noisy, irregular time series but traditionally require slow numerical solvers to sample between arbitrary time points. We introduce Neural Stochastic Flows, which learn SDE transitions directly, enabling fast one-step sampling with large speedups while preserving accuracy on synthetic and real-world data.

Instant Policy: In-Context Imitation Learning via Graph Diffusion
Vitalis Vosylius and Edward Johns
Published at ICLR 2025 (oral)
Mini abstract. Instant Policy achieves in-context learning for immediate learning of a new skill after just one or two demonstrations. We formulate this as a graph generation problem, and use simulated pseudo-demonstrations for a virtually infinite pool of training data.

R+X: Retrieval and Execution from Everyday Human Videos
Georgios Papagiannis, Norman Di Palo, Pietro Vitiello, and Edward Johns
Published at ICRA 2025
Mini abstract. R+X enables robots to learn skills from long, unlabelled first-person videos of humans performing everyday tasks. Given a language command from a human, R+X first retrieves short video clips containing relevant behaviour, and then conditions an in-context imitation learning technique (KAT) on this behaviour to execute the skill.
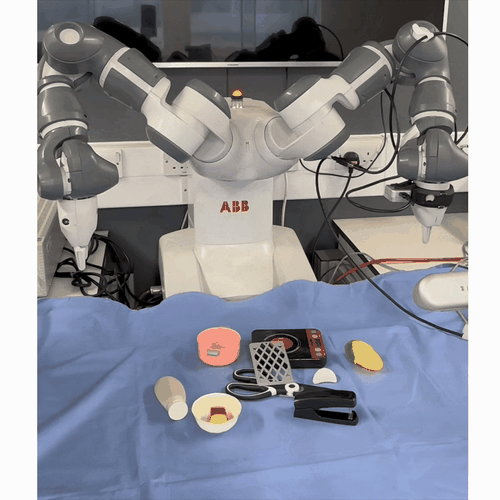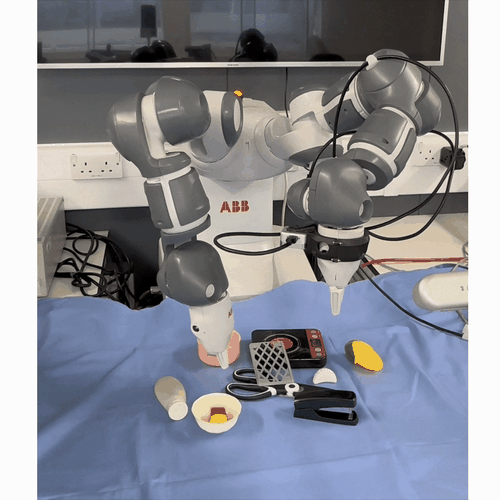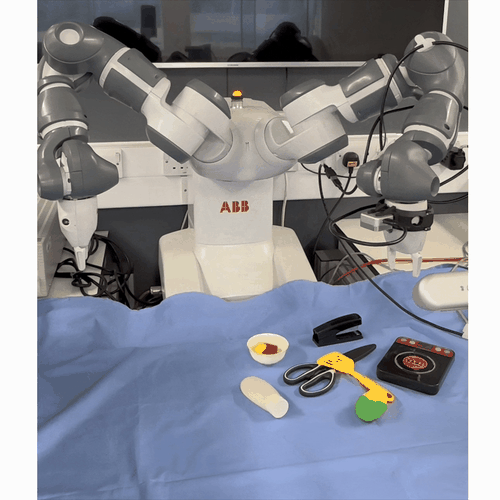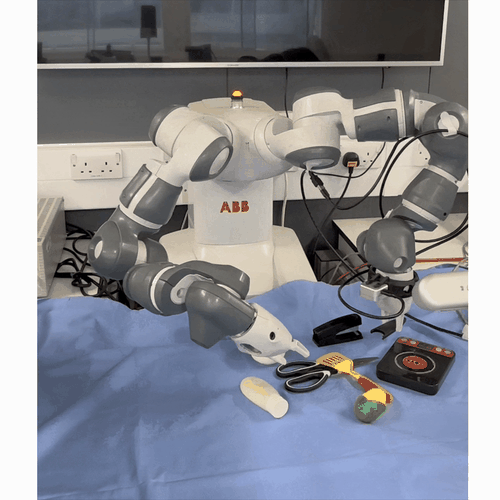
One-Shot Dual-Arm Imitation Learning
Yilong Wang and Edward Johns
Published at ICRA 2025
Mini abstract. We develop a framework that enables robots to learn dual-arm tasks from just a single demonstration. This uses a three-stage visual servoing method for precise alignment between the end-effector and target object, followed by replay of the demonstration trajectory.

MILES: Making Imitation Learning Easy with Self-Supervision
Georgios Papagiannis and Edward Johns
Published at CoRL 2024
Mini abstract. We show that self-supervised learning enables robots to learn vision-based policies for precise, complex tasks, such as locking a lock with a key, from just a single demonstration and one environment reset. The self-supervised data collection generates augmentation trajectories which show the robot how to return to, and then follow, the single demonstration.

Adapting Skills to Novel Grasps: A Self-Supervised Approach
Georgios Papagiannis, Kamil Dreczkowski, Vitalis Vosylius, and Edward Johns
Published at IROS 2024
Mini abstract. If a robot learns a skills with a grasped object (e.g. a tool), then that skill will usually fail if the robot grasps the object in a different way to when it learned the skill. In this work, we introduce a self-supervised data collection method, which enables a robot to adapt a skill to a novel grasp even though the skill was learned using a different grasp.

Keypoint Action Tokens Enable In-Context Imitation Learning in Robotics
Norman Di Palo and Edward Johns
Published at RSS 2024
Mini abstract. By representing observations and actions as 3D keypoints, we can just feed demonstrations into an LLM for in-context imitation learning, using the LLM's inherent pattern recognition ability. This is a very different "LLMs + Robotics" idea to usual: rather than using LLMs for high-level reasoning with natural language, we use LLMs for low-level reasoning with numerical keypoints.

Language Models as Zero-Shot Trajectory Generators
Teyun Kwon, Norman Di Palo, and Edward Johns
Published in RA-Letters 2024
Mini abstract. Can LLMs predict dense robot trajectories, using only internal reasoning? We study if a single, task-agnostic prompt, can enable an LLM to solve a range of tasks when given access to an object detector, without requiring any action primitives, in-context examples, or external trajectory optimisers.

Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Ivan Kapelyukh, Yifei Ren, and Edward Johns
Published at ICRA 2024
Mini abstract. Dream2Real enables robots to "dream" in 3D using NeRFs, and "evaluate" in 2D using VLMs. First, an object-centric NeRF of a scene is created. Then, 2D images of plausible reconfigurations of the scene are rendered, and evaluated with respect to a language command using CLIP. Finally, the robot recreates the configuration with the best score via pick-and-place.

DINOBot: Robot Manipulation via Retrieval and Alignment with Vision Foundation Models
Norman Di Palo and Edward Johns
Published at ICRA 2024
Mini abstract. DINOBot is an efficient imitation learning framework, which can learn tasks in a single demonstration, whilst also generalising to novel objects from that single demonstration. We use DINO features to understand both (1) how to generalise to novel objects ("retrieval", using image-level features), and (2) how to interact with those novel objects ("alignment", using pixel-level features).

Prismer: A Vision-Language Model with Multi-Task Experts
Shikun Liu, Linxi Fan, Edward Johns, Zhiding Yu, Chaowei Xiao, and Anima Anandkumar
Published in TMLR 2024
Mini abstract. Prismer is a data- and parameter-efficient vision-language model that leverages an ensemble of diverse, pre-trained task-specific experts. Prismer achieves fine-tuned and few-shot learning vision-language reasoning performance which is competitive with current state-of-the-arts, whilst requiring up to two orders of magnitude less training data.

On the Effectiveness of Retrieval, Alignment, and Replay in Manipulation
Norman Di Palo and Edward Johns
Published in RA-Letters 2024
Mini abstract. We study the taxonomy of recent imitation learning methods, across two axes: whether generalisation is achieved via retrieval or via interpolation, and whether or not a trajectory is decomposed into "approaching" and "interacting" phases. And we show that, for efficient learning with a single demonstration per object, the optimal combination is "retreval, alignment, and replay".

Few-Shot In-Context Imitation Learning via Implicit Graph Alignment
Vitalis Vosylius and Edward Johns
Published at CoRL 2023
Mini abstract. We show that, by deforming random objects in simulation, we can easily generate a large set of virtual demonstrations for tasks requiring generalisation across object shapes. This diverse training data then allows us to predict the quality of a test alignment of objects when conditioned on demonstration alignments, hence achieving few-shot in-context imitation learning.

One-Shot Imitation Learning: A Pose Estimation Perspective
Pietro Vitiello, Kamil Dreczkowski, and Edward Johns
Published at CoRL 2023
Mini abstract. We study a novel combination of trajectory transfer and unseen object pose estimation, which enables new tasks to be learned from just a single demonstration, without requiring any further data collection or training. Under this formulation, experiments provide a deep dive into the effects of pose estimation errors and camera calibration errors on task success rates.

DALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics
Ivan Kapelyukh, Vitalis Vosylius, and Edward Johns
Published in RA-Letters 2023
Mini abstract. We present the first work to study web-based diffusion models for robotics. DALL-E-Bot achieves zero-shot object rearrangement, by first inferring a text string describing the objects in a scene, then prompting DALL-E with this string to generate a goal image, and then rearranging the objects to recreate this image.

Real-time Mapping of Physical Scene Properties with an Autonomous Robot Experimenter
Iain Haughton, Edgar Sucar, Andre Mouton, Edward Johns, and Andrew Davison
Published at CoRL 2022 (oral)
Mini abstract. We study how 3D neural fields can be used to map physical object properties, such as object rigidity, material type, and required pushing force. Our method enables a robot to autonomously explore and experiment with an object, whilst simultaneously scanning the object and mapping acquired data via a learned 3D neural field.

Where To Start? Transferring Simple Skills to Complex Environments
Vitalis Vosylius and Edward Johns
Published at CoRL 2022
Mini abstract. Most robot skills, such as grasping or placing objects, are trained in simple, clutter-free environments. Here, we introduce an affordance model based on a graph representation of a more complex scene, which predicts good robot configurations to start such a skill from, such that executing it from here would avoid any collisions.

Eugene Valassakis, Georgios Papagiannis, Norman Di Palo, and Edward Johns
Published at IROS 2022
Mini abstract. We introduce an imitation learning method called DOME, which enables tasks on novel objects to be learned from a single demonstration, without requiring any further training or data collection. This is made possible by training in advance, purely in simulation, an object segmentation network and a visual servoing network.

Auto-λ: Disentangling Dynamic Task Relationships
Shikun Liu, Stephen James, Andrew J. Davison, and Edward Johns
Published in TMLR 2022
Mini abstract. We present Auto-Lambda, a method to dynamically adapt task weightings during multi-task learning or auxiliary-task learning. This is achieved through a meta-learning formulation where weightings automatically adapt based on the validation loss. Evaluation is done on several computer vision and simulated robotics tasks.

Bootstrapping Semantic Segmentation with Regional Contrast
Shikun Liu, Shuaifeng Zhi, Edward Johns, and Andrew J. Davison
Published at ICLR 2022
Mini abstract. We present ReCo, a contrastive learning framework designed to assist learning in semantic segmentation. ReCo performs semi-supervised or supervised pixel-level contrastive learning on a sparse set of hard negative pixels, and enables semantic segmentation with just a few human labels.

Learning Multi-Stage Tasks with One Demonstration via Self-Replay
Norman Di Palo and Edward Johns
Published at CoRL 2021
Mini abstract. We propose a method which allows a multi-stage task, such as a pick-and-place operation, to be learned from a single human demonstration, without any prior knowledge of the objects. Following a demonstration, the robot uses self-replay to collect a self-supervised image dataset, for each stage of the task.
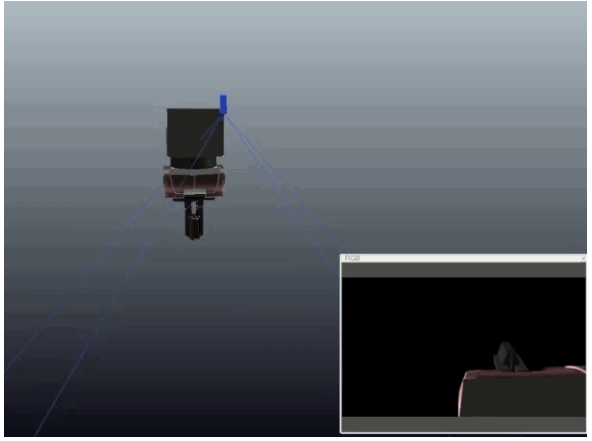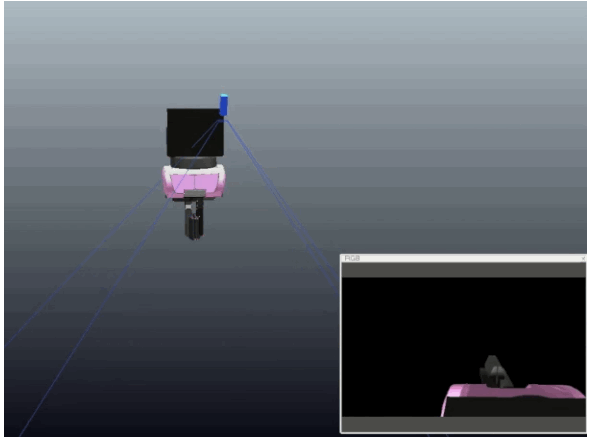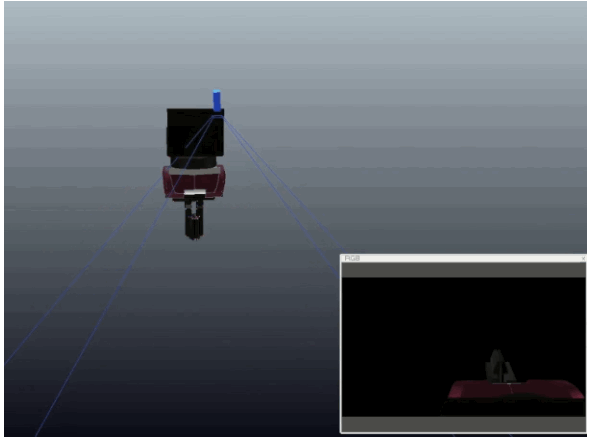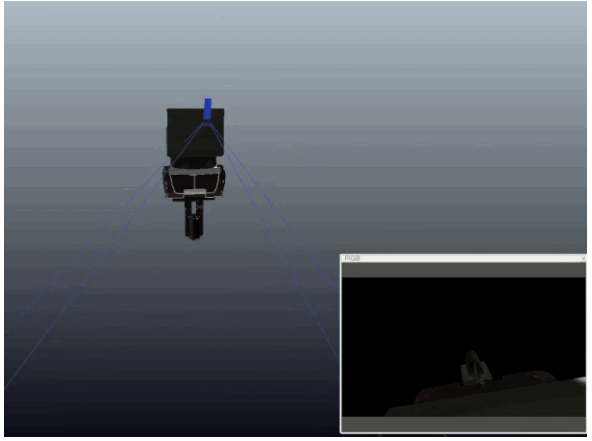
Learning Eye-in-Hand Camera Calibration from a Single Image
Eugene Valassakis, Kamil Dreczkowski, and Edward Johns
Published at CoRL 2021
Mini abstract. We study a range of different learning-based methods for extrinsic calibration of a wrist-mounted RGB camera, when given only a single RGB image from that camera. We found that a simple direct regression of calibration parameters performed the best, and also outperformed classical calibration methods based on markers.

My House, My Rules: Learning Tidying Preferences with Graph Neural Networks
Ivan Kapelyukh and Edward Johns
Published at CoRL 2021
Mini abstract. We propose a method for object re-arrangement, which can adapt to each person's individual preferences for how objects should be arranged. The method trains a variational auto-encoder, which learns a latent "user preference" vector at the bottleneck. Objects are encoded using a graph neural network.

Back to Reality for Imitation Learning
Edward Johns
Published at CoRL 2021 (Blue sky oral track)
Mini abstract. Evaluation metrics for robot learning are deeply rooted in those for machine learning, and focus primarily on data efficiency. We believe that a better metric for real-world robot learning is time efficiency, which better models the true cost to humans. This is a call to arms to the community to develop our own metrics.

Coarse-to-Fine for Sim-to-Real: Sub-Millimetre Precision Across Wide Task Spaces
Eugene Valassakis, Norman Di Palo, and Edward Johns
Published at IROS 2021
Mini abstract. We develop a framework which allows for precise sub-millimetre control for zero-shot sim-to-real transfer, whilst also enabling interaction across a wide range of object poses. Each trajectory involves first a coarse, ICP-based planning stage, followed by a fine, end-to-end visuomotor control stage.

Kamil Dreczkowski, and Edward Johns
Published at IROS 2021
Mini abstract. ICP algorithms typically involve a fixed choice of data association method and a fixed choice of error metric. In this paper, we propose a novel and flexible ICP variant, which dynamically optimises both the data association method and error metric based on the live image of an object and the current ICP estimate.

Coarse-to-Fine Imitation Learning: Robot Manipulation from a Single Demonstration
Edward Johns
Published at ICRA 2021
Mini abstract. We propose a method for visual imitation learning, which can learn novel, everyday tasks, from just a single human demonstration. First, sequential state estimation aligns the end-effector with the object, which is trained with self-supervised learning, and second, the robot simply replays the original demonstration velocities.

DROID: Minimizing the Reality Gap using Single-Shot Human Demonstration
Ya-Yen Tsai, Hui Xu, Zihan Ding, Chong Zhang, Edward Johns, and Bidan Huang
Published at RA-Letters and ICRA 2021
Mini Abstract. We introduce a dynamics sim-to-real method, which exploits a single real-world demonstration. Simulation parameters are optimised by attempting to align the simulated and real-world demonstration trajectories. An RL-based policy can then be trained in simulation and applied directly to the real world.

Benchmarking Domain Randomisation for Visual Sim-to-Real Transfer
Raghad Alghonaim and Edward Johns
Published at ICRA 2021
Mini Abstract. We benchmark the design choices in domain randomisation for visual sim-to-real. Evaluation is done on a simple pose estimation task. Results show that a small number of high-quality images is better than a large number of low-quality images, and that both random textures and random distractors are effective.

Crossing the Gap: A Deep Dive into Zero-Shot Sim-to-Real Transfer for Dynamics
Eugene Valassakis, Zihan Ding, and Edward Johns
Published at IROS 2020
Mini Abstract. We benchmark sim-to-real for tasks with complex dynamics, where no real-world training is available. We show that previous works require significant simulator tuning to achieve transfer. A simple method which just injects random forces, outperforms domain randomisation whilst being significantly easier to tune.

Physics-Based Dexterous Manipulations with Estimated Hand Poses and Residual Reinforcement Learning
Guillermo Garcia-Hernando, Edward Johns, and Tae-Kyun Kim
Published at IROS 2020
Mini Abstract. We introduce a method for dexterous object manipulation in a virtual environment, using a hand pose estimator in the real world. Residual reinforcement learning, trained in a physics simulator, learns to correct the noisy pose estimator. Rewards use adversarial imitation learning, to encourage natural motion.

Shape Adaptor: A Learnable Resizing Module
Shikun Liu, Zhe Lin, Yilin Wang, Jianming Zhang, Federico Perazzi, and Edward Johns
Published at ECCV 2020
Mini Abstract. We introduce a method to optimise a neural network's shape for a given dataset. Traditional resizing layers, such as max-pooling and striding, use a fixed resizing ratio based on heuristics, whereas we can now train these ratios end-to-end. Results show improvements over hand-engineered network architectures.

Sim-to-Real Transfer for Optical Tactile Sensing
Zihan Ding, Nathan Lepora, and Edward Johns
Published at ICRA 2020
Mini Abstract. We train a TacTip optical tactile sensor to detect edge positions and orientations. Training is done with simulated data using a soft-body model, and transfer to the real world is achieved by randomising simulator parameters. Real-world tests show that edge positions can be predicted with an error of less than 1mm.

Constrained-Space Optimization and Reinforcement Learning for Complex Tasks
Ya-Yen Tsai, Bo Xiao, Edward Johns, and Guang-Zhong Yang
Published in RA-Letters and ICRA 2020
Mini Abstract. We train a robot to perform a complex sewing task. Human demonstrations are used to create a constrained space, and reinforcement learning in simulation optimises a trajectory by exploring this space. Real-world experiments show that this optimised trajectory is superior to any one of the individual demonstrations.

Self-supervised Generalisation with Meta Auxiliary Learning
Shikun Liu, Andrew Davison, and Edward Johns
Published at NeurIPS 2019
Mini Abstract. We train a CNN for image recognition, using automatically-generated auxiliary labels. A second CNN generates these auxiliary labels using meta learning, by encouraging labels which assist the primary task. Experiments show that the performance on the primary task is as good as using human-defined auxiliary labels.

End-to-End Multi-Task Learning with Attention
Shikun Liu, Edward Johns, and Andrew Davison
Published at CVPR 2019
Mini Abstract. We train a multi-task CNN which can share features across different tasks. A common trunk of features is learned, and each task applies a soft attention mask to the common pool, where the attention masks are learned end-to-end. Our method achieves state-of-the-art performance on dense image prediction.

Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task
Stephen James, Andrew J. Davison, and Edward Johns
Published at CoRL 2017
Mini Abstract. We train an end-to-end robot controller to grasp a cube from multiple positions, and drop it into a basket. Training is done in simulation with behavioural cloning, and is transferred to the real world with domain randomisation. In real-world experiments, we show robustness to distractor objects and illumination changes.

Deep Learning a Grasp Function for Grasping under Gripper Pose Uncertainty
Edward Johns, Stefan Leutenegger, and Andrew Davison
Published at IROS 2016
Mini Abstract. We train a robot to grasp novel objects using depth images. Data is collected in simulation by attempting grasps across a wide range of objects. A CNN is trained to predict the grasp quality across a regular grid of gripper poses, which is combined with the gripper's pose uncertainty to create a robust grasp.

Pairwise Decomposition of Image Sequences for Active Multi-View Recognition
Edward Johns, Stefan Leutenegger, and Andrew Davison
Published at CVPR 2016 (oral)
Mini Abstract. We propose a multi-view object recognition pipeline which can recognise objects over arbitrary camera trajectories. Image sequences are decomposed into pairs for pairwise classification with a CNN, and a second CNN is trained to predict the next-best view. State-of-the-art results are achieved on ModelNet.