Key Idea We formulate In-Context Imitation Learning as a graph generation problem and use simulated pseudo-demonstrations as a main source of training data, enabling robots to acquire skills instantaneously after just one or two demonstrations.

Abstract
Video Overview
Following the impressive capabilities of in-context learning with large transformers, In-Context Imitation Learning (ICIL) is a promising opportunity for robotics. We introduce Instant Policy, which learns new tasks instantly from just one or two demonstrations, achieving ICIL through two key components. First, we introduce inductive biases through a graph representation and model ICIL as a graph generation problem using a learned diffusion process, enabling structured reasoning over demonstrations, observations, and actions. Second, we show that such a model can be trained using pseudo-demonstrations – arbitrary trajectories generated in simulation – as a virtually infinite pool of training data. Our experiments, in both simulation and reality, show that Instant Policy enables rapid learning of various everyday robot tasks. We also show how it can serve as a foundation for cross-embodiment and zero-shot transfer to language-defined tasks.
Graph Representation
To achieve efficient and generalisable In-Context Imitation Learning, we first need to choose a suitable representation that would capture the key elements of the problem and introduce appropriate inductive biases. We propose a heterogeneous graph that jointly expresses context, current observation, and future actions, capturing complex relationships between the robot and the environment and ensuring that the relevant information is aggregated and propagated in a meaningful manner. This graph is constructed using segmented point cloud observations, as shown in the figure below.

In-Context Imitation Learning as a Graph Generation Problem
To utilise our graph representation effectively, we frame In-Context Imitation Learning as a graph generation problem and learn a distribution over previously described graphs using a diffusion model, depicted in the figure below. This approach involves forward and backward Markov-chain processes, where the graph is altered and reconstructed in each phase. Intuitively, during training, we add some noise to our representation and learn to remove it.

At test time, starting from actions sampled from a normal distribution, the model iteratively updates only the parts of the graph representing robot actions, implicitly modelling the desired conditional action probability. Here, you can see the visualisation of such a denoising process when the positions of the gripper nodes representing robot actions are visualised with respect to the point cloud observation. In this case, 8 actions in the future are predicted (different colours represent different action timesteps in the future).

An Infinite Pool of Data
Unlike traditional Behavioural Cloning, which encodes tasks directly into the weights of a neural network, In-Context Imitation Learning defines tasks through the provided context, allowing the model to interpret and act based on a few examples. Leveraging this paradigm shift, we introduce pseudo-demonstrations—arbitrary yet semantically consistent, procedurally generated robot trajectories—as a virtually limitless source of training data. Here, consistent means that while the generated trajectories differ, they `perform' the same type of pseudo-task at a semantic level. Some of these generated pseudo-demonstrations can be used as context while inferring actions associated with the left-out one, making them suitable for In-Context Learning. This approach allows abundant data generation with minimal human effort, creating new opportunities for efficient robot learning. Examples of the pseudo-demonstrations for different pseudo-tasks can be seen in the visualisation below.
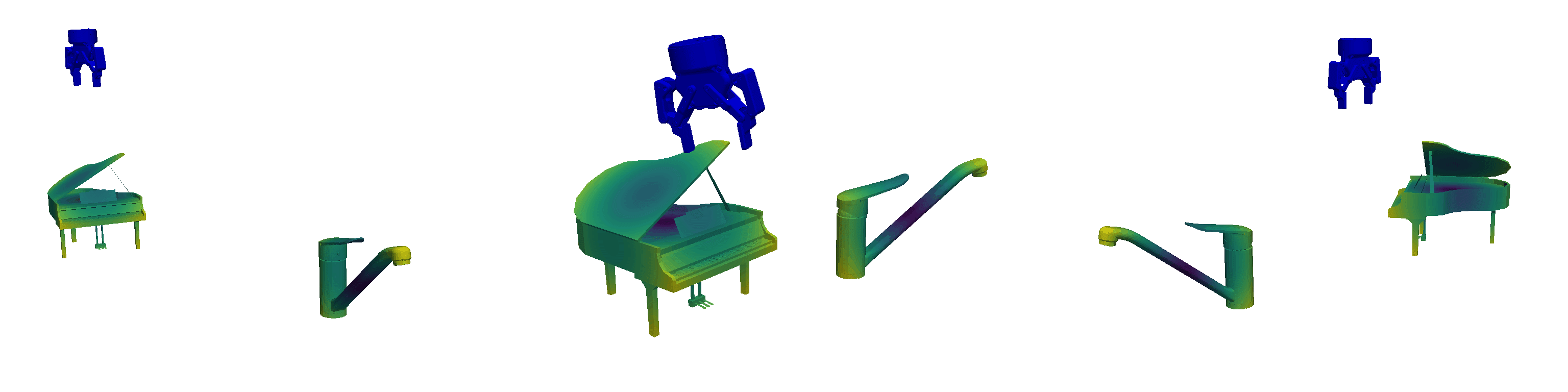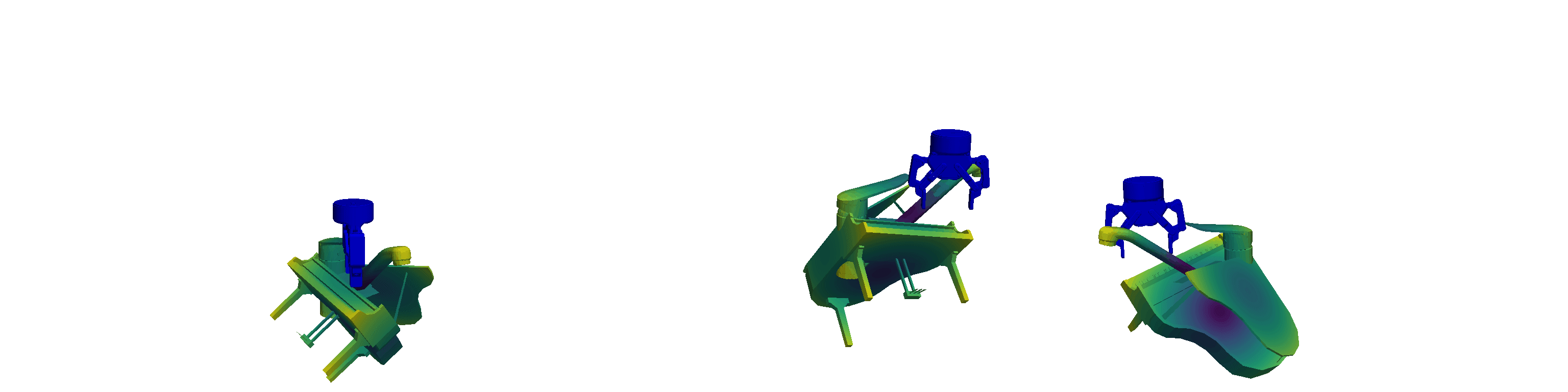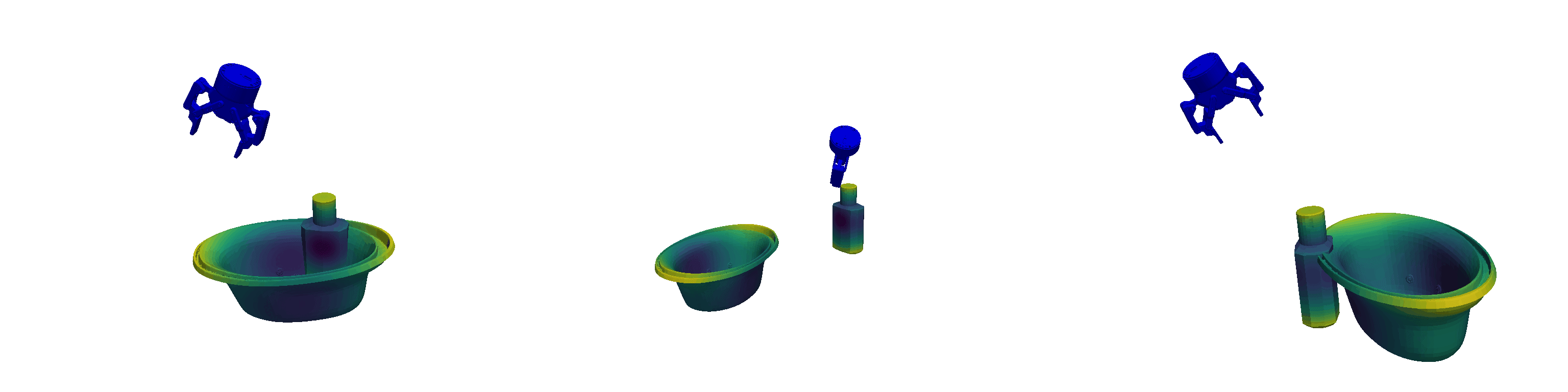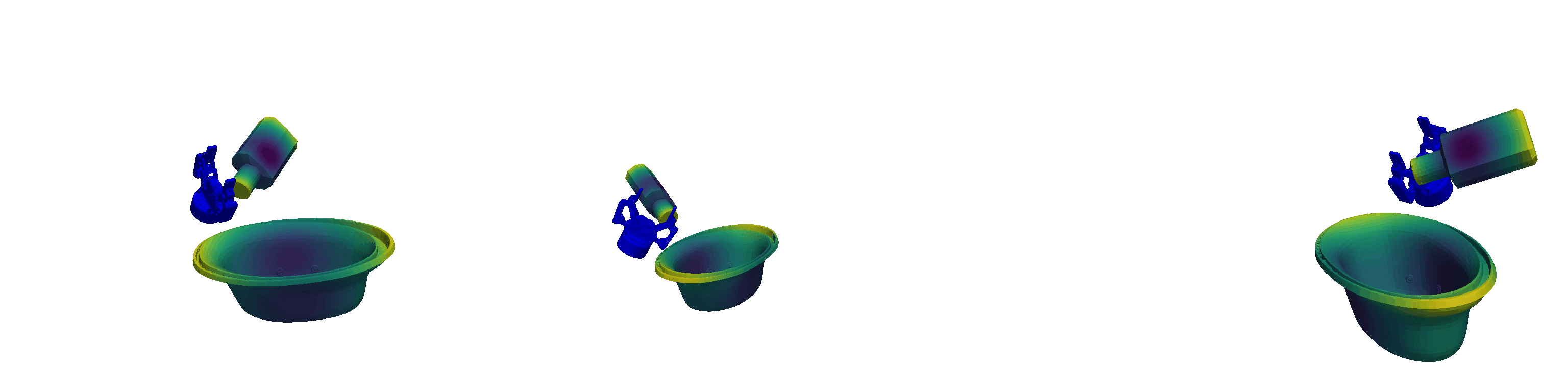
Robust and Generalisable Policies
Deploying Instant Policy on a real robot using just one or a few demonstrations results in robust and generalisable closed-loop manipulation policies! Below, you can see Instant Policy being deployed with external perturbations introduced by either moving the objects in the environments or the robot itself.
Insert Paper Roll

<<< swipe for more tasks >>>
Emergent Generalisation Properties
The ability to add an arbitrary number of demonstrations to the context together with a structured graph representation allows Instant Policy to selectively aggregate and interpolate the information present in the context to disambiguate the task and the parts of the objects that are relevant to it. This results in an emergent generalisation capability to generalise to different object geometries from the ones used during the demonstrations. From the video below, we can see that Instant Policy initially fails to open a box with a different geometry at deployment. However, when more demonstrations with different boxes are provided, it is capable of disambiguating the task and generalising to different boxes at test time.
Open Box

<<< swipe for more tasks >>>
Understanding the Context
One might ask where this robustness comes from. To investigate this, we visualise the attention weights on the edges of the graph that are responsible for interpreting and aggregating relevant information from the context for placing a phone on a base task in simulation (see video below). We can see that Instant Policy is able to understand at what stage of a task it is at and focus on relevant parts of the context -- initially focusing on the grasping point in the demonstration, and once the phone is grasped, shifting the attention towards the placing point.

Cross-Embodiment Transfer
Since our model uses segmented point clouds and defines the robot state by the end-effector pose and gripper state, different embodiments can be used to define the context and roll out the policy, provided the mapping between them is known. We define such a mapping between human hands and robot gripper using Mediapipe and transfer the policy directly to the robot while the demonstrations (i.e. the context) are provided using human hands.

Modality Change to Language
We can further use our trained model as a foundation for completing various manipulation tasks defined by language zero-shot, completely circumventing the need for demonstrations at test time. We achieve this using a smaller language-annotated dataset and approximating the information bottleneck of our model, which holds the information about the context and the current observation needed to predict robot actions. Using this information approximation and deploying Instant Policy allows us to define the context using language and instantaneously deploy the resulting policy, as shown in the video below.

Learn More About Instant Policy!